 Pythonサンプルコードを見ていると「if __name__ == ‘__main__’」と記述されていることがよくありますよね? 意味が分からないと、その時点でコード解読離脱してしまいます。 本記事では、 […]]]>
Pythonサンプルコードを見ていると「if __name__ == ‘__main__’」と記述されていることがよくありますよね? 意味が分からないと、その時点でコード解読離脱してしまいます。 本記事では、 […]]]>
Pythonサンプルコードを見ていると「if __name__ == ‘__main__’」と記述されていることがよくありますよね?
意味が分からないと、その時点でコード解読離脱してしまいます。
本記事では、この構文が何を意味し、どんなときに使うのかを解説します。
Python学習を始めたばかりの人
if __name__ == ‘__main__’の意味と用途
if __name__ == ‘__main__’の意味は、もしPythonコードが直接実行されたときは以降のコードを処理し、モジュールとして呼び出されたときは処理しないです。
用途は、モジュールを呼び出したときに、勝手に処理が実行されることを防ぐことです。また、モジュールの単体テスト用としても使われます。コードを直接実行したときと、モジュールとして他のコードから呼び出されたときの処理を分けることでモジュールの単体テストを可能とします。
モジュールの単体テスト用ですから、Pythonコードが1ファイルの場合は、この構文は必要ありません。
次項では、Pythonコードが直接実行されたときのみ処理する仕組みを解説します。
__name__変数とは
__name__変数とは、モジュール名を返す特別な変数です。importで他のコードから呼び出された場合は、__name__はファイル名となります。一方、コードを直接実行した場合は、__name__はファイル名となります。
サンプルプログラムで確認していきましょう。
モジュール「module.py」とメインコード「main.py」を用意しました。
def func():
return __name__
if __name__ == '__main__':
print('__name__ = ' + func())import module
print('__name__ = ' + module.func())それぞれのファイルを実行してみますと下表のようになったのではないでしょうか?
| 実行ファイル | module.py | main.py |
|---|---|---|
| __name__ | __main__ | module |
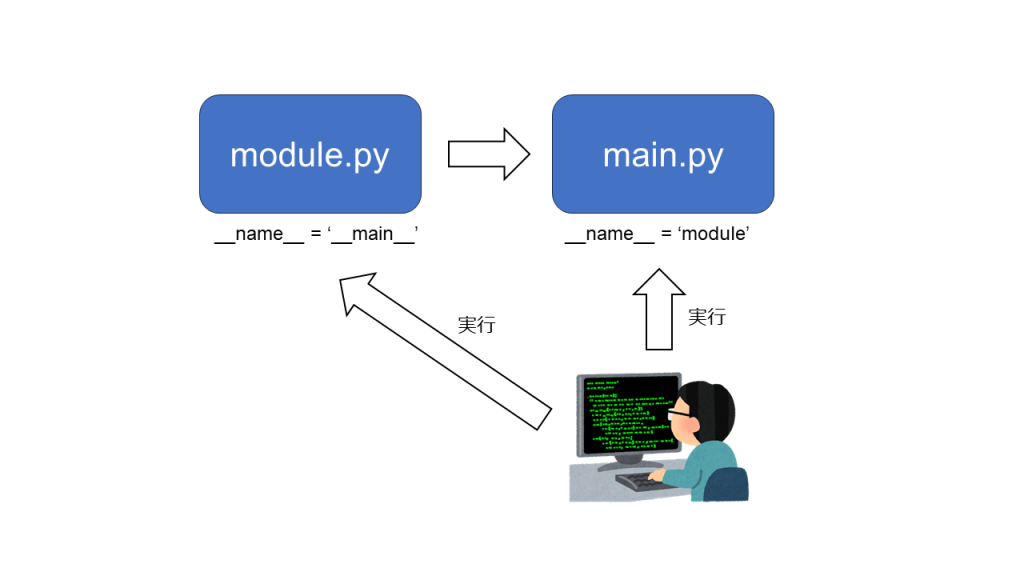
main.pyからmodule.pyをimportしたときは、”if name == ‘main’:” 以降の処理が実行されないのがお分かりですね。
まとめ
Pythonサンプルコードでよく見る「if __name__ == ‘__main__’」の意味と用途について解説しました。
意味
- もしPythonコードが直接実行されたときは以降のコードを処理し、モジュールとして呼び出されたときは処理しない
用途
- モジュールを呼び出したときに、勝手に処理が実行されることを防ぐ
- モジュールの単体テスト用
今回の記事が皆さんのPython学習に役立つなら幸いです。
Python独学が大変な方は、書籍やスクールを活用するのも手です。
以前の記事でOpenCVで顔検出するプログラムを解説しました。 今回は、顔検出の応用として、目と笑顔を検出する方法について解説します。 サンプルプログラム こちらが目、笑顔を検出するサンプルプログラムです。 実行結果がこ […]]]>
以前の記事でOpenCVで顔検出するプログラムを解説しました。

今回は、顔検出の応用として、目と笑顔を検出する方法について解説します。
サンプルプログラム
こちらが目、笑顔を検出するサンプルプログラムです。
import cv2 as cv
# カスケード分類器読み込み
frontalface_cascade = cv.CascadeClassifier("haarcascade_frontalface_default.xml")
eye_cascade = cv.CascadeClassifier("haarcascade_eye.xml")
smile_cascade = cv.CascadeClassifier("haarcascade_smile.xml")
# 画像の読み込み
img = cv.imread("sample.jpg")
# 顔検出
face = frontalface_cascade.detectMultiScale(img)
# 顔部を赤枠で囲む
for x, y, w, h in face:
cv.rectangle(img,(x,y), (x+w, y+h), (0,0,255), 1)
# 顔部の上3/4を切り取り
upper_face_img = img[y:int(y+3*h/4), x:x+w]
# 目検出
eye = eye_cascade.detectMultiScale(upper_face_img)
# 目部を青枠で囲む
for x1, y1, w1, h1 in eye:
cv.rectangle(img, (x+x1,y+y1), (x+x1+w1, y+y1+h1), (255,0,0), 1)
# 顔部の下半分を切り取り
under_face_img = img[int(y+h/2):(y+h), x:x+w]
# 笑顔検出
smile = smile_cascade.detectMultiScale(under_face_img)
# 笑顔を緑枠で囲む
for x2, y2, w2, h2 in smile:
cv.rectangle(img,(x+x2, int(y+h/2)+y2), (x+x2+w2, int(y+h/2)+y2+h2), (0,255,0), 1)
cv.imshow("img", img)
cv.waitKey(0)
cv.destroyAllWindows()実行結果がこちら

3人とも目が検出できました。右2人は笑っているので、口元が笑顔と判定されています。
次章ではサンプルプログラムを解説していきます。
プログラム解説
サンプルプログラムの流れは以下のとおりとなっています。
STEP1~3は、別記事で解説していますので、本記事では割愛しました。
ここでは、STEP4: 目の検出、STEP5: 笑顔の検出について解説していきます。
目の検出
目を検出するには「haarcascade_eye.xml」を使用します。
# カスケード分類器読み込み
eye_cascade = cv.CascadeClassifier("haarcascade_eye.xml")
# 顔部の上3/4を切り取り
upper_face_img = img[y:int(y+3*h/4), x:x+w]
# 目検出
eye = eye_cascade.detectMultiScale(upper_face_img)
# 目部を青枠で囲む
for x1, y1, w1, h1 in eye:
cv.rectangle(img, (x+x1,y+y1), (x+x1+w1, y+y1+h1), (255,0,0), 1)mg)顔部の上3/4を切り取り、この中から目を検出して青枠で囲むということをしています。
もし、顔部を切り取らなかったらどうなるのでしょうか?
下図は顔部を切り取らなかった場合の実行結果です。

左の女性のおでこと口が目と誤判定されてしまいました。目は顔の上部に位置していますので、誤判定しないためにも検出範囲を顔の上部のみに絞る方が良いことが分かります。
笑顔の検出
笑顔を検出するのは「haarcascade_smile.xml」です。
# カスケード分類器読み込み
smile_cascade = cv.CascadeClassifier("haarcascade_smile.xml")
# 顔部の下半分を切り取り
under_face_img = img[int(y+h/2):(y+h), x:x+w]
# 笑顔検出
smile = smile_cascade.detectMultiScale(under_face_img)
# 笑顔を緑枠で囲む
for x2, y2, w2, h2 in smile:
cv.rectangle(img,(x+x2, int(y+h/2)+y2), (x+x2+w2, int(y+h/2)+y2+h2), (0,255,0), 1)目の検出同様、顔部の下半分を切り取り、この中から笑顔を検出して緑枠で囲みます。
こちらも顔部を切り取らなかった場合を確認してみましょう。

様々なところで笑顔が検出されてしまいました。検出範囲を絞ることが重要です!
色々な画像で目・笑顔の検出
こちらの画像では右側女性の右目が検出出来ませんでした。

こちらの写真は3人とも笑顔ではないですが、口元が笑顔と検出されています。

笑顔検出というよりは、口検出に近いですね。
まとめ
顔検出の応用として、OpenCVの「カスケード分類器」を使用した目・笑顔検出プログラムについて解説しました。
手順のおさらい
- カスケード分類器読み込み
- 画像の読み込み
- 顔の検出
- 目の検出
- 笑顔の検出
今回の記事が皆さんのPython学習に役立つなら幸いです。
Python独学が大変な方は、書籍やスクールを活用するのも手です。
 PythonからGoogle Calendarの予定を取得する方法を学んだので記事にしました。 まず、環境セットアップ方法について解説します。次に、Pythonを使って現在時刻から先の予定を取得する方法について解説します […]]]>
PythonからGoogle Calendarの予定を取得する方法を学んだので記事にしました。 まず、環境セットアップ方法について解説します。次に、Pythonを使って現在時刻から先の予定を取得する方法について解説します […]]]>
PythonからGoogle Calendarの予定を取得する方法を学んだので記事にしました。
まず、環境セットアップ方法について解説します。次に、Pythonを使って現在時刻から先の予定を取得する方法について解説します。
それでは始めましょう!
この記事はこんな人におすすめ!
- Google Calendarから予定を取得するプログラムを作りたい人
- Python初心者
環境セットアップ方法
PythonからGoogle Calendarを操作するには、Googleが公開しているGoogle Calendar APIを利用する必要があります。
そのため、Pythonスクリプトを作成する前に以下の事前準備が必要となります。
- Google Cloud Platformでプロジェクトを新規作成する
- Google Calendar APIを有効にする
- OAuthクライアントIDの作成
- OAuth同意画面の設定
- Google クライアント ライブラリをインストール
Google Cloud Platformでプロジェクトを新規作成
Google Calendar APIは、Google Cloud PlatformというGoogleが提供するクラウドコンピューティングサービスで有効化することができます。
これらを有効化するには新規プロジェクトを作成しなければいけません。
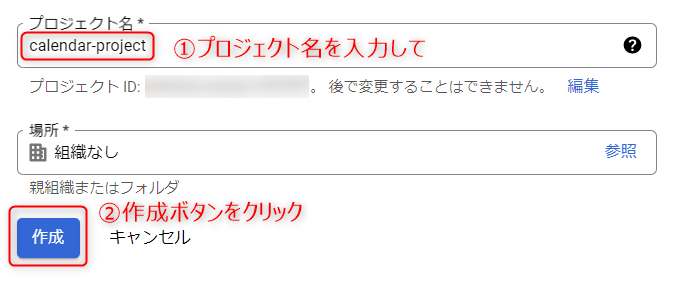
Google Cloud Platformのページを開き、左上のバーを選択して新しいプロジェクトを選択しましょう。


プロジェクト名を入力して作成ボタンを押すと、新規プロジェクトが作成できます。
Google Calendar APIを有効化
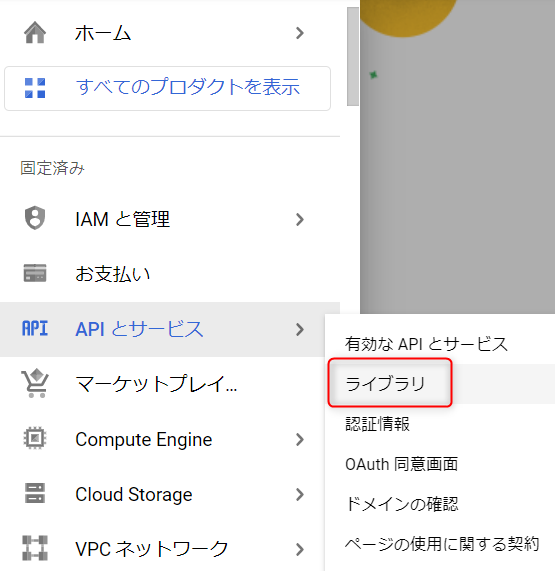
続いてGoogle Calendar APIを有効化します。
「APIとサービス」→「ライブラリ」を選択します。
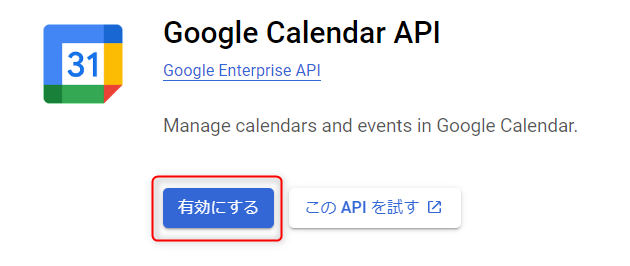
Google Calendar APIを検索し、有効にします。
OAuthクライアントIDの作成
PythonスクリプトからGoogle CalendarにアクセスするにはクライアントIDを取得する必要があります。
[APIとサービス]>[認証情報]>[認証情報を作成]>[OAuthクライアントID]をクリック。
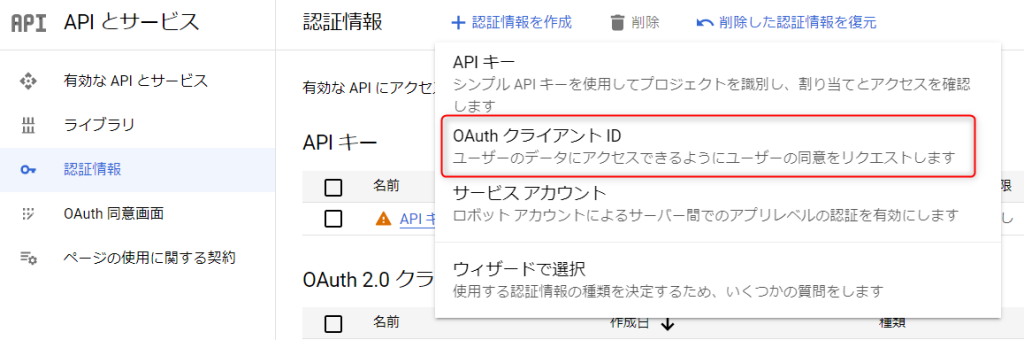
アプリケーションの種類は「デスクトップアプリ」を選択。名前は適当に入力し、作成をクリックします。
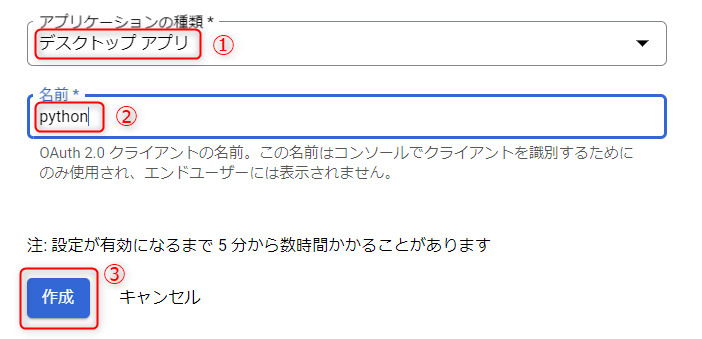
JSONファイルをダウンロードしておきましょう。
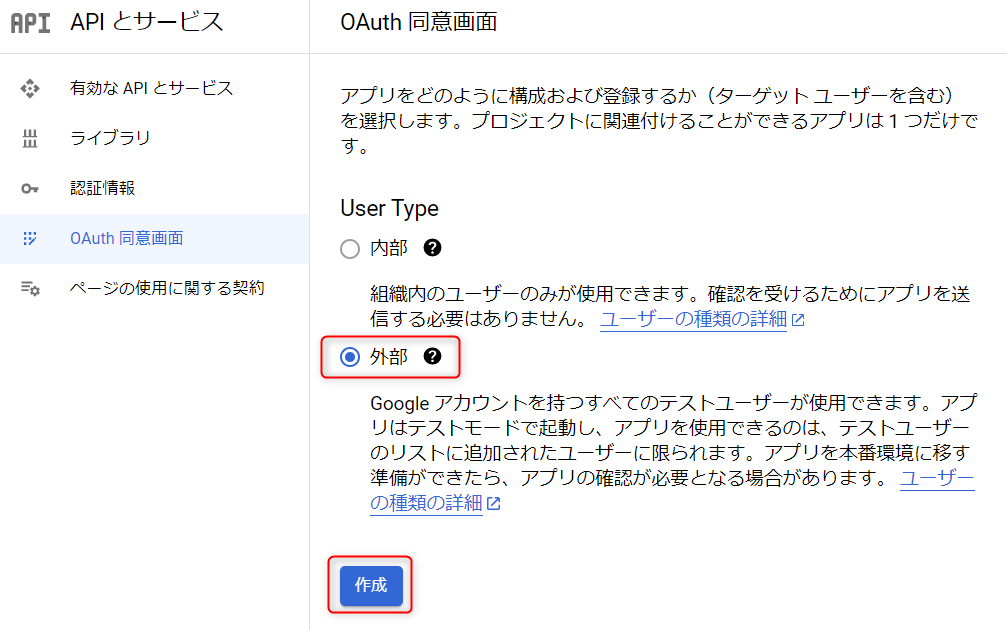
OAuth同意画面の設定
PythonからGoogle CalendarにアクセスするとGoogleの同意画面が表示されます。その際の同意画面を設定します。
メニューの[OAuth同意画面]からUser Type「外部」を選択し、「作成ボタン」をクリックします。
アプリ名、ユーザーサポートメール、デベロッパーの連絡先情報を入力して、「保存して次へ」ボタンをクリック。
続いてアクセス権を設定します。
Google クライアント ライブラリをインストール
今度はPython側の準備です。Googleクライアントライブラリをインストールします。
ターミナルで以下のように打つとGoogleクライアントライブラリがインストールできます。
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlibPythonを使って現在時刻から先の予定を取得
ここからはPythonスクリプトの解説です。
サンプルスクリプト
下記は現在時刻から先の予定を取得するPythonサンプルスクリプトです。
from __future__ import print_function
import datetime
import os.path
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
SCOPES = ['https://www.googleapis.com/auth/calendar.readonly']
def main():
creds = None
# token.pickleファイルにユーザーアクセストークンとリフレッシュトークンが保存され、
# 認証が初めてのときにtoken.pickleは自動的に作成される
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
# 資格情報が有効でなければ、ユーザーログインさせる
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
# 次回実行時には認証が省略される
with open('token.json', 'w') as token:
token.write(creds.to_json())
try:
service = build('calendar', 'v3', credentials=creds)
# Calendar情報の取得
now = datetime.datetime.now().isoformat() + 'Z'
print('現在時刻から先の予定を10個取得')
events_result = service.events().list(calendarId='******@group.calendar.google.com', timeMin=now,
maxResults=10, singleEvents=True,
orderBy='startTime').execute()
events = events_result.get('items', [])
if not events:
print('予定が1つもありませんでした')
return
# 取得したカレンダー情報を表示
for event in events:
start = event['start'].get('dateTime', event['start'].get('date'))
print(start, event['summary'], event['location'], event['description'])
except HttpError as error:
print('An error occurred: %s' % error)
if __name__ == '__main__':
main()最初にGoogle認証を行ったのち、現在時刻から先の予定を10件まで取得します。
スクリプト解説
現在時刻から先の予定を取得
下記は予定を取得する部分です。
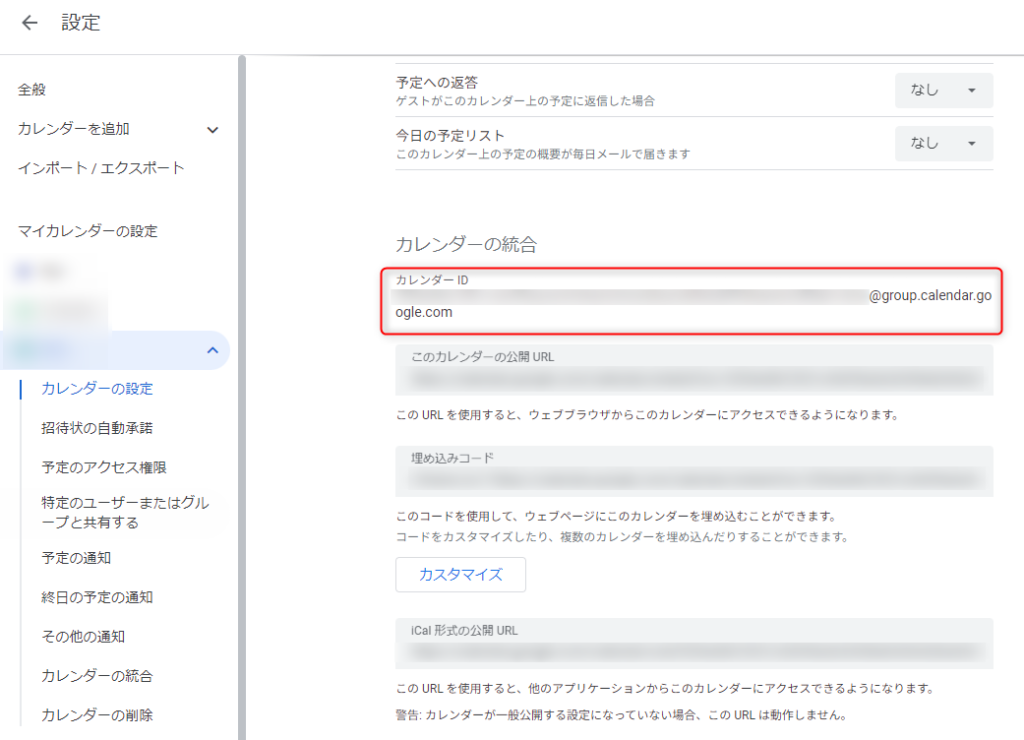
events_result = service.events().list(calendarId='******@group.calendar.google.com', timeMin=now,
maxResults=10, singleEvents=True,
orderBy='startTime').execute()
events = events_result.get('items', [])calendarIdは何を設定すればいいの?
予定名・時間・場所・説明を表示
下記は予定を表示する部分です。
for event in events:
start = event['start'].get('dateTime', event['start'].get('date'))
print(start, event['summary'], event['location'], event['description'])startは開始時刻、summaryは予定名、locationは場所、descriptionは説明です。
実行結果
それではPythonスクリプトを実行していきましょう!
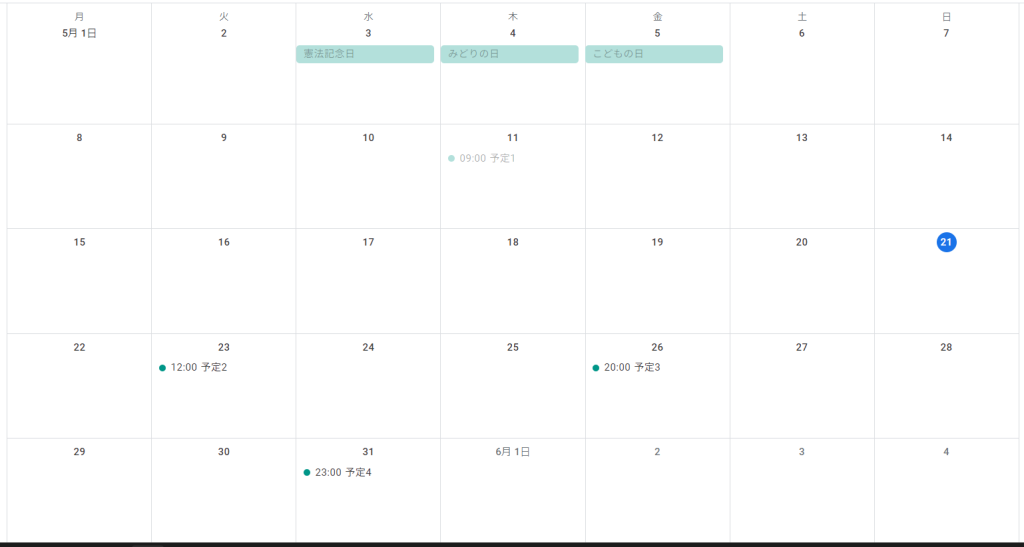
Google Calendarには下図の予定1~4を追加しています。本日は5/21なので、予定2~4が取得できるはずです。
Pythonスクリプトを実行するとWebブラウザが立ち上がり、アカウントの選択が求められます。
アクセス許可したアカウントを選択しましょう。
自作アプリのため、「このアプリはGoogleで確認されていません」と表示されます。警告を無視して「続行」ボタンを押しましょう。
次も「続行」ボタンを押します。
ターミナルを見て下さい。予定2~4の時間、場所、説明がターミナル上に表示されるはずです。
2023-05-23T12:00:00+09:00 予定2 新宿 ランチ
2023-05-26T20:00:00+09:00 予定3 六本木 ディナー
2023-05-31T23:00:00+09:00 予定4 浅草 ジムまとめ
PythonからGoogle Calendarの予定を取得する方法について解説しました。
- Google Calendar APIの環境セットアップ
- 現在時刻から先の予定を取得するPythonスクリプトの実践
この記事がPythonを学ぶ皆さんのためになれば幸いです。
独学が大変な方は、書籍やスクールを活用するのも手です。私も活用しているものを載せておきますので参考にして下さい。
最後までお読み頂きありがとうございました!
 物体のエッジを抽出するプログラムを作りたいが、どのように作ればよいか分からない。エッジ抽出の原理について詳しく知りたい。 そんな悩みを解消すべく本記事では、ノイズを除去しつつエッジ抽出するソーベルフィルタについて解説しま […]]]>
物体のエッジを抽出するプログラムを作りたいが、どのように作ればよいか分からない。エッジ抽出の原理について詳しく知りたい。 そんな悩みを解消すべく本記事では、ノイズを除去しつつエッジ抽出するソーベルフィルタについて解説しま […]]]>
物体のエッジを抽出するプログラムを作りたいが、どのように作ればよいか分からない。エッジ抽出の原理について詳しく知りたい。
そんな悩みを解消すべく本記事では、ノイズを除去しつつエッジ抽出するソーベルフィルタについて解説します。
まず、エッジ抽出原理を解説します。次にソーベルフィルタとは何かについての解説です。最後にPython,OpenCVを用いて画像のエッジを抽出するプログラムを解説します。
それでは始めましょう!
この記事はこんな人におすすめ!
- 画像処理を学んでいる初心者
- エッジ抽出の技術を理解したい人
- プログラミングで画像処理を実践したい人

エッジ抽出の原理
ソーベルフィルタについて理解するためには、エッジ抽出の原理を学ぶ必要があります。ここでは、微分によってエッジ検出する原理を解説します。
微分で勾配を数値化
画像処理でのエッジとは、画像の明るい部分と暗い部分が急激に変化する勾配部です。この勾配部を抽出するには、画像の輝度値を微分し数値化します。関数\(f(x)\)の微分\(f'(x)\)は以下式で表されますよね。
$$f'(x)=\lim_{h \to 0}\frac{f(x+h)-f(x)}{h}$$
下図のように、輝度値を微分した値が大きい部分がエッジに相当することが分かります。
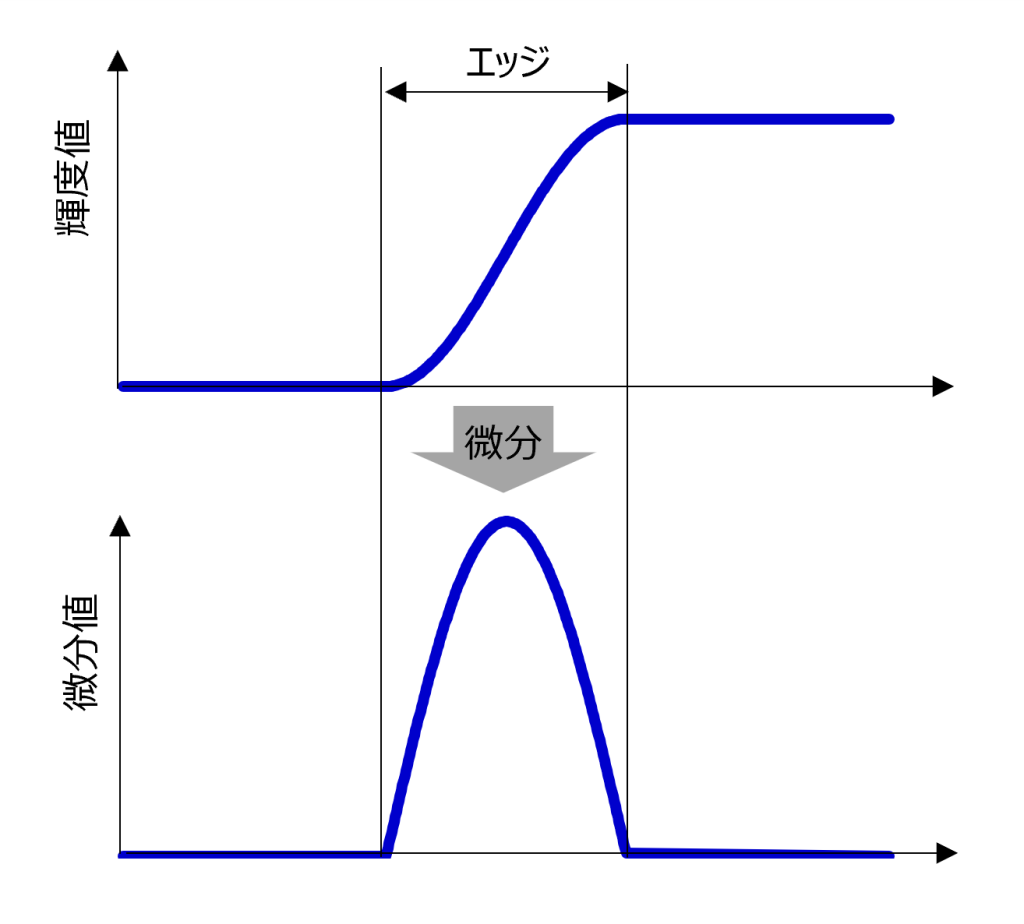
デジタル画像は2変数かつ1画素ごとの値のため、どうやったら勾配を求められる?
偏微分
2変数関数の場合は、微分する変数を1つ指定し、それ以外の変数を定数として微分します。このような微分を偏微分といいます。2変数関数を\(f(x,y)\)とし、xで微分した導関数を\(f_x(x,y)\)、yで微分した導関数を\(f_y(x,y)\)とすると
$$f_x(x,y) = \lim_{h \to 0}\frac{f(x+h, y)-f(x, y)}{h}$$
$$f_y(x,y) = \lim_{h \to 0}\frac{f(x, y+h)-f(x, y)}{h}$$
\(f_x(x,y)\)はx方向、\(f_y(x,y)\)はy方向の勾配を表します。
微分の離散化
デジタル画像は、1画素ごとの離散値です。そのため、\(h\)は有限です。そこで、\(h=1\)として微分値を求めます。
$$f_x(x,y) = f(x+1, y)-f(x, y)$$
$$f_y(x,y) = f(x, y+1)-f(x, y)$$
これは座標\((x,y)\)とその前方座標\((x+1,y)、(x,y+1)\)の差分をとっていますので前方差分と呼ばれます。
一方、\(h=-1\)の場合は
$$f_x(x,y) = f(x, y)-f(x-1, y)$$
$$f_y(x,y) = f(x, y)-f(x, y-1)$$
となり、座標\((x,y)\)とその前方座標\((x-1,y)\)、\((x,y-1)\)の差分をとることから後方差分と呼ばれます。
また、前方差分と後方差分の平均を求めると
$$f_x(x,y) = \frac{f(x+1, y)-f(x-1, y)}{2}$$
$$f_y(x,y) = \frac{f(x, y+1)-f(x, y-1)}{2}$$
となります。座標\((x+1,y)\)と座標\((x-1,y)\)の差分、座標\((x,y+1)\)と座標\((x,y-1)\)の差分をとることから中心差分と呼ばれます。
微分フィルタ
空間フィルタリングにおいて線形フィルタは、入力画像を\(f(i,j)\)、出力画像を\(g(i,j)\)、フィルタ係数を\(h(m,n)\)とするとき、以下式で表されました。
$$g(i,j)=\sum_{n=-W}^{W}\sum_{m=-W}^{W}f(i+m,j+n)h(m,n)$$
https://craft-gogo.com/gauss-fillter/
微分をこの形式で表すと微分フィルタは以下表となります。
| x方向 | y方向 | |
| 前方差分 | \begin{pmatrix} 0 & 0 & 0 \\ 0 & -1 & 1 \\ 0 & 0 & 0 \end{pmatrix} | \begin{pmatrix} 0 & 0 & 0 \\ 0 & -1 & 0 \\ 0 & 1 & 0 \end{pmatrix} |
| 後方差分 | \begin{pmatrix} 0 & 0 & 0 \\ -1 & 1 & 0 \\ 0 & 0 & 0 \end{pmatrix} | \begin{pmatrix} 0 & -1 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \end{pmatrix} |
| 中心差分 | \begin{pmatrix} 0 & 0 & 0 \\ -1/2 & 0 & 1/2 \\ 0 & 0 & 0 \end{pmatrix} | \begin{pmatrix} 0 & -1/2 & 0 \\ 0 & 0 & 0 \\ 0 & 1/2 & 0 \end{pmatrix} |
ソーベルフィルタとは
画像にノイズが混入していると、ノイズをエッジと誤検出してしまいます。
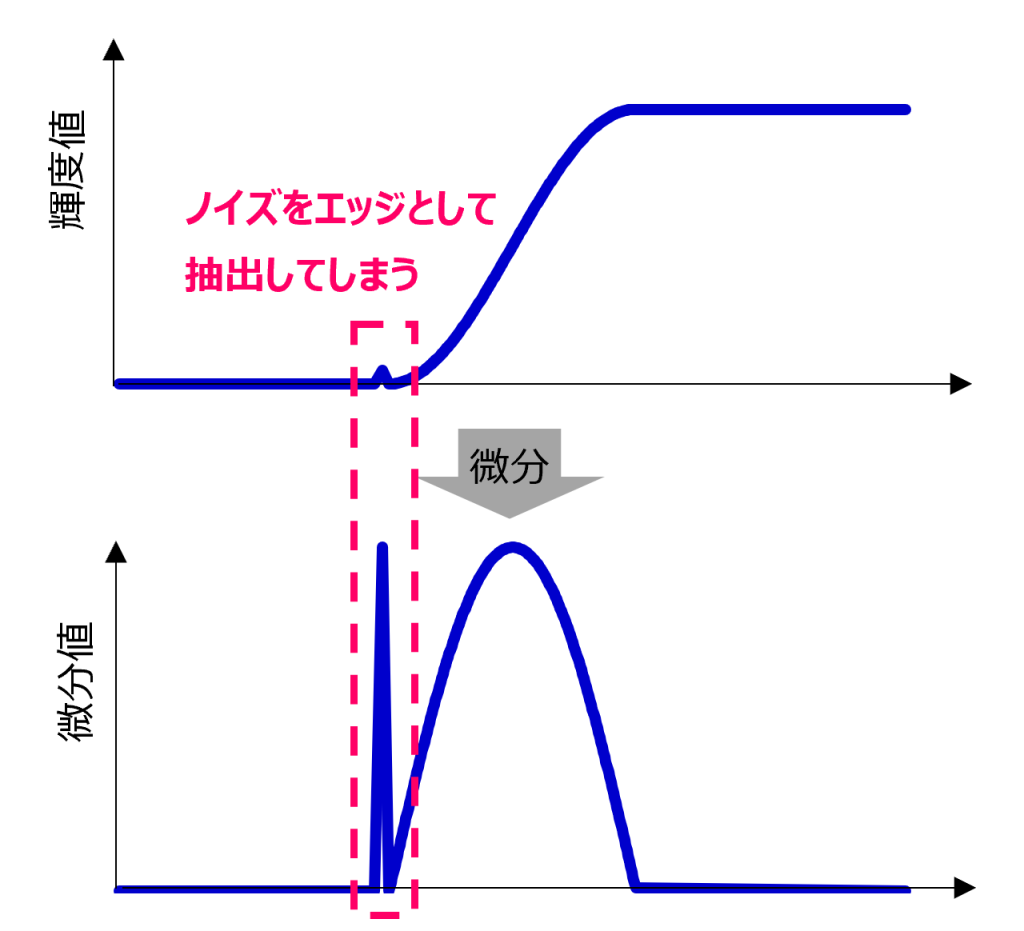
そこで登場するのが、ノイズを除去しつつエッジ抽出するソーベルフィルタです。
そこで登場するのがソーベルフィルタです。ソーベルフィルタとは、前節で説明した中央差分したのち、中央に重み付けした平滑化を行ったフィルタです。
フィルタ係数
下記表は、x方向、y方向の中央差分、重み付き平滑化、ソーベルフィルタのフィルタ係数です。
| 中央差分: \(h_1(x,y)\) | 重み付き平滑化: \(h_2(x,y)\) | ソーベルフィルタ: \(h_2(x,y)\cdot h_1(x,y)\) | |
| x方向 | \(\begin{pmatrix} 0 & 0 & 0 \\ -\frac{1}{2} & 0 & \frac{1}{2} \\ 0 & 0 & 0 \end{pmatrix}\) | \(\begin{pmatrix} 0 & \frac{1}{4} & 0 \\ 0 & \frac{2}{4} & 0 \\ 0 & \frac{1}{4} & 0 \end{pmatrix}\) | \(\frac{1}{8}\begin{pmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{pmatrix}\) |
| y方向 | \(\begin{pmatrix} 0 & -\frac{1}{2} & 0 \\ 0 & 0 & 0 \\ 0 & \frac{1}{2} & 0 \end{pmatrix}\) | \(\begin{pmatrix} 0 & 0 & 0 \\ \frac{1}{4} & \frac{2}{4} & \frac{1}{4} \\ 0 & 0 & 0 \end{pmatrix}\) | \(\frac{1}{8}\begin{pmatrix} -1 & -2 & 1 \\ 0 & 0 & 0 \\ -1 & 2 & 1 \end{pmatrix}\) |
中央差分を\(h_1(x,y)\)、重み付き平滑化を\(h_2(x,y)\)とするとき、中央差分と重み付き平滑化を順に施したソーベルフィルタは、\(h_2(x,y)\cdot h_1(x,y)\)で計算できます。
ブリューウィットフィルタとの違い
ソーベルフィルタと同様なフィルタにブリューウィットフィルタ(Prewitt filter)というものがありますので紹介しておきます。
| 中央差分: \(h_1(x,y)\) | 平滑化: \(h_2(x,y)\) | ブリューウィットフィルタ: \(h_2(x,y)\cdot h_1(x,y)\) | |
| x方向 | \(\begin{pmatrix} 0 & 0 & 0 \\ -\frac{1}{2} & 0 & \frac{1}{2} \\ 0 & 0 & 0 \end{pmatrix}\) | \(\begin{pmatrix} 0 & \frac{1}{3} & 0 \\ 0 & \frac{1}{3} & 0 \\ 0 & \frac{1}{3} & 0 \end{pmatrix}\) | \(\frac{1}{6}\begin{pmatrix} -1 & 0 & 1 \\ -1 & 0 & 1 \\ -1 & 0 & 1 \end{pmatrix}\) |
| y方向 | \(\begin{pmatrix} 0 & -\frac{1}{2} & 0 \\ 0 & 0 & 0 \\ 0 & \frac{1}{2} & 0 \end{pmatrix}\) | \(\begin{pmatrix} 0 & 0 & 0 \\ \frac{1}{3} & \frac{1}{3} & \frac{1}{3} \\ 0 & 0 & 0 \end{pmatrix}\) | \(\frac{1}{6}\begin{pmatrix} -1 & -1 & 1 \\ 0 & 0 & 0 \\ -1 & 1 & 1 \end{pmatrix}\) |
こちらは中央差分と重みなしの平滑化を順に施したフィルタです。
OpenCVを用いたエッジ抽出
では、PythonとOpenCVを用いて画像のエッジを抽出してみましょう。
サンプルプログラム
下記は、画像を読み込み、ソーベルフィルタを適用したサンプルプログラムです。
import cv2 as cv
def concat_tile(im_list_2d):
return cv.vconcat([cv.hconcat(im_list_h) for im_list_h in im_list_2d])
img = cv.imread("sample.jpg") # 写真の読み込み
img_sobelx = cv.Sobel(img, cv.CV_64F, 1, 0, ksize=3) # 3x3の横方向ソーベルフィルタ
img_sobelx = cv.convertScaleAbs(img_sobelx)
img_sobely = cv.Sobel(img, cv.CV_64F, 0, 1, ksize=3) # 3x3の縦方向ソーベルフィルタ
img_sobely = cv.convertScaleAbs(img_sobely)
img_gradient = cv.addWeighted(img_sobelx, 0.5, img_sobely, 0.5, 0) # 勾配の大きさ
imgs = concat_tile([[img, img_sobelx], [img_sobely, img_gradient]])
cv.imshow("img", imgs)
cv.imwrite("output.jpg", imgs)
if cv.waitKey(0) & 0xFF == ord('q'):
cv.destroyAllWindows()実行結果

左上が元画像、右上が横方向エッジ抽出、左下が縦方向のエッジ抽出、右下が勾配の大きさになります。
花の輪郭が抽出されているのが分かりますよね。
プログラム解説
サンプルプログラムを解説していきましょう。
ソーベルフィルタ適用は、cv.Sobel()関数を呼び出します。
cv.Sobel(img, cv.CV_64F, 1, 0, ksize=3)第1引数に読み込む画像、第2引数は、出力画像のビット深度を指定します。第3,4引数はx,yに関する微分の次数です。(1, 0)でx方向、(0, 1)でy方向のエッジが抽出できます。ksizeはフィルタ係数の大きさです。今回は3×3のフィルタサイズを指定しました。
ソーベルフィルタは微分値をとるため、負の値にもなります。しかし、負の値が含まれていると画像表示することが出来ません。そこで、cv.convertScaleAbs()関数を呼び出して絶対値にします。
cv.convertScaleAbs(img)縦方向と横方向のエッジを合成するには、cv.addWeighted()関数を呼び出します。
cv.addWeighted(src1, alpha1, src2, beta, gamma)出力結果は、\(\alpha\cdot src1 + \beta \cdot src2 + \gamma\)となります。
まとめ
今回は、ノイズを除去しつつエッジ抽出するソーベルフィルタについて解説しました。
- 微分によってエッジ検出する
- ソーベルフィルタとは、中央差分したのち、中央に重み付けした平滑化を行ったフィルタ
- OpenCVのcv.Sobel()関数によって、ソーベルフィルタを適用できる
これで、物体のエッジを抽出するプログラムが簡単に作れますね。
この記事が画像処理を学ぶ皆さんのためになれば幸いです。
独学が大変な方は、書籍やスクールを活用するのも手です。私も活用しているものを載せておきますので参考にして下さい。
最後までお読み頂きありがとうございました!
 画像のごま塩ノイズを除去したい。そんなときはメディアンフィルタの登場です。本記事では、ノイズを除去するメディアンフィルタについて解説します。 メディアンフィルタとは メディアンフィルタとは空間フィルタリングの一種です。 […]]]>
画像のごま塩ノイズを除去したい。そんなときはメディアンフィルタの登場です。本記事では、ノイズを除去するメディアンフィルタについて解説します。 メディアンフィルタとは メディアンフィルタとは空間フィルタリングの一種です。 […]]]>
画像のごま塩ノイズを除去したい。そんなときはメディアンフィルタの登場です。本記事では、ノイズを除去するメディアンフィルタについて解説します。
この記事はこんな人におすすめ!
- 画像処理を学んでいる初心者
- ノイズ除去の技術を理解したい人
- プログラミングで画像処理を実践したい人
メディアンフィルタとは
メディアンフィルタとは空間フィルタリングの一種です。
メディアン(median)とは中央値のこと。メディアンフィルタは、周辺画素の画素値を降(昇)順に並べ、中央値を出力します。周辺画素に対して著しく外れた値(ノイズ)は、メディアンフィルタを通過すると除去されます。
下図は3×3メディアンフィルタでノイズが除去されるイメージ図です。
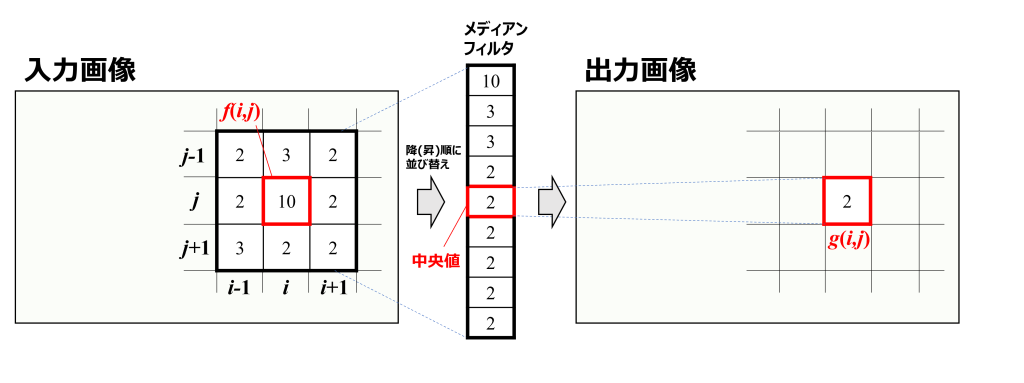
座標(i,j)の画素は上下左右斜めに対して著しく外れた「10」ですが、メディアンフィルタを通過すると、上下左右斜めの画素中央値である「2」に変換され、ノイズが除去されることが分かります。
OpenCVを用いたノイズ除去
PythonとOpenCVライブラリを用いれば、簡単にメディアンフィルタで画像のノイズを除去することが出来ます。
こちらがメディアンフィルタのPythonサンプルプログラムです。
import cv2 as cv
def concat_tile(im_list_2d):
return cv.vconcat([cv.hconcat(im_list_h) for im_list_h in im_list_2d])
img = cv.imread("sample.jpg") # 写真の読み込み
img_median3 = cv.medianBlur(img, 3) # 3x3のメディアンフィルタ
img_median5 = cv.medianBlur(img, 5) # 5x5のメディアンフィルタ
img_median7 = cv.medianBlur(img, 7) # 7x7のメディアンフィルタ
imgs = concat_tile([[img, img_median3], [img_median5, img_median7]])
cv.imshow("img", imgs)
cv.imwrite("output.jpg", imgs)
if cv.waitKey(0) & 0xFF == ord('q'):
cv.destroyAllWindows()左上が元画像。右上、左下、右下がそれぞれ3×3、5×5、7×7のメディアンフィルタを適用した画像となります。

3×3フィルタサイズで、ごま塩ノイズが十分除去されていることが分かりますね。フィルタサイズを大きくしすぎると、画像全体がぼやけてしまうので注意が必要です。
cv.medianBlur(img, N) # NxNのメディアンフィルタ第1引数に入力画像、第2引数にフィルタサイズを設定します。
ガウシアンフィルタとの比較
ぼかしの基本であるガウシアンフィルタでも、ごま塩ノイズが除去できるか試してみましょう。
ガウシアンフィルタについては、下記リンク先参照して下さい。
https://craft-gogo.com/gauss-fillter/
左上が元画像。右上、左下、右下がそれぞれσ=1、σ=2、σ=3のガウシアンフィルタを適用した画像です。

σを大きくしないと、ごま塩ノイズは除去できないことが分かります。ごま塩ノイズ除去できたとしても、画像はかなりぼやけてしまいますね。
まとめ
本記事では、ノイズを除去するメディアンフィルタについて解説しました。
画像のごま塩ノイズを除去したければ、メディアンフィルタを適用すればよいことが分かりましたね。
この記事が画像処理を学ぶ皆さんのためになれば幸いです。
独学が大変な方は、書籍やスクールを活用するのも手です。私も活用しているものを載せておきますので参考にして下さい。
最後までお読み頂きありがとうございました!
 写真の主役を引き立たせるために背景をぼかしたり、プライバシー保護のため写真の顔をぼかしたりしますよね? Photoshopなどの画像処理ソフトで画像をぼかそうとすると、種類がたくさんあって何を使ったらいいものか̷ […]]]>
写真の主役を引き立たせるために背景をぼかしたり、プライバシー保護のため写真の顔をぼかしたりしますよね? Photoshopなどの画像処理ソフトで画像をぼかそうとすると、種類がたくさんあって何を使ったらいいものか̷ […]]]>
写真の主役を引き立たせるために背景をぼかしたり、プライバシー保護のため写真の顔をぼかしたりしますよね?
Photoshopなどの画像処理ソフトで画像をぼかそうとすると、種類がたくさんあって何を使ったらいいものか…。
本記事では、ぼかしの基本であるボックスフィルタ、ガウシアンフィルタについて解説します。また、PythonとOpenCVで実際に写真をぼかす実践をします。この記事を読めば、画像をぼかしたかったら、悩まずガウシアンフィルタを選択すれば無難なことが分かります。
もう、ぼかしで悩むことから脱却しましょう!
この記事はこんな人におすすめ!
- 画像処理を学んでいる初心者
- ぼかしの技術を理解したい人
- プログラミングで画像処理を実践したい人
空間フィルタリングとは
概念
ぼかしを学ぶ前に空間フィルタリングを理解する必要があります。フィルタを直訳すると、ろ過器やこし器などです。画像処理では、画像をこの空間フィルタで処理することで様々な画像に変換します。空間フィルタには、ぼかすためのフィルタ、エッジを抽出するためのフィルタ、ノイズを除去するためのフィルタなどがあります。
空間フィルタの概念は、コーヒーの抽出で例えることができます。コーヒーは、コーヒーの粉をコーヒーフィルタに入れ、お湯を注ぐと作ることができますよね。澄んだお湯がコーヒーフィルタを介すと黒く濁ったコーヒーになる。空間フィルタリングも同様なイメージです。入力画像は、お湯です。空間フィルタリングは、コーヒーフィルタです。コーヒーの粉は、ぼかしフィルタなどフィルタの種類です。出力画像は、コーヒーです。入力画像をぼかしフィルタで処理すると、出力画像は入力画像がぼけた結果になります。

空間フィルタは、線形フィルタと非線形フィルタに分けられます。ボックスフィルタ、ガウシアンフィルタは線形フィルタのため、ここでは線形フィルタについて解説していきます。
線形フィルタの数式
線形フィルタは、入力画像を\(f(i,j)\)、出力画像を\(g(i,j)\)とするとき、以下の式により計算されます。
$$g(i,j)=\sum_{n=-W}^{W}\sum_{m=-W}^{W}f(i+m,j+n)h(m,n)$$
\(h(m,n)\)はフィルタの係数を表す配列であり、フィルタの種類によってこの配列は変わってきます。ボックスフィルタ、ガウシアンフィルタの係数は次章で詳しく説明します。
フィルタの大きさは、\((2W+1)\times (2W+1)\)です。\(W=1\)の場合、\(3\times 3\)行列、\(W=2\)の場合、\(5\times 5\)行列となります。
数式見てもイメージしづらいですよね…。
計算例
そこで数式に具体的な数値を代入し、イメージしやすくしましょう。下図は3×3フィルタの計算例です。
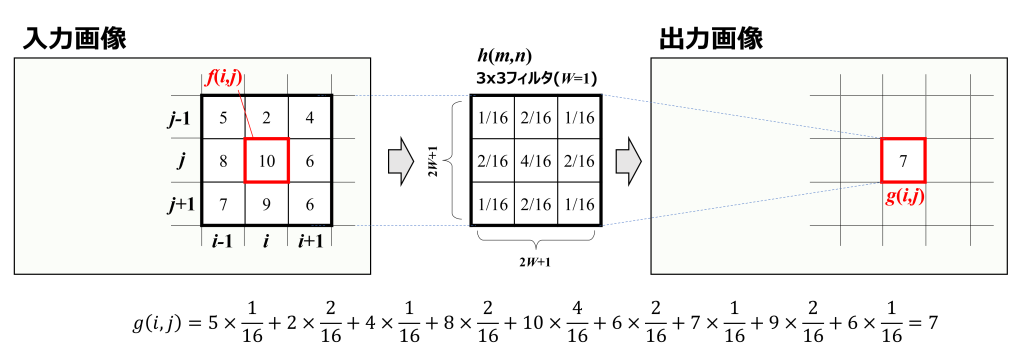
入力画像の(i,j)座標の画素は「10」でしたが、フィルタを通すと(i,j)座標の画素は「7」となります。
3×3フィルタの場合は、入力画像のある画素に対して、上下左右斜めの8画素が影響し出力画素となっていますよね。これが空間フィルタリングと呼ばれる理由です。
空間フィルタリングの知識は身に付いたと思いますので、画像をぼかすためのボックスフィルタ、ガウシアンフィルタについて解説していきます。
ボックスフィルタとは
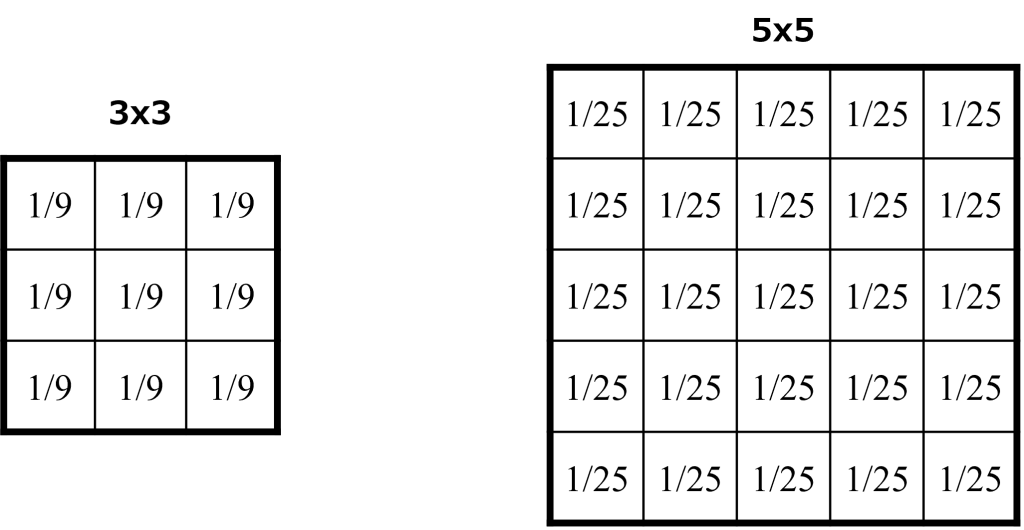
ボックスフィルタは、非常に簡単なぼかし(平滑化)フィルタです。フィルタの範囲を平均化するのみです。3×3フィルタの場合は、3×3=9画素をフィルタしますので、各フィルタ係数は9分の1となります。同様に5×5フィルタの場合は、各フィルタ係数は25分の1となります。
ガウシアンフィルタとは
ガウシアンフィルタは、フィルタ係数がガウス分布となっているものです。
ガウス分布?
1次元のガウス分布は以下式で表されます。σは標準偏差です。
$$h_g (x) = \frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{x^2}{2\sigma^2})$$
グラフにすると下図です。
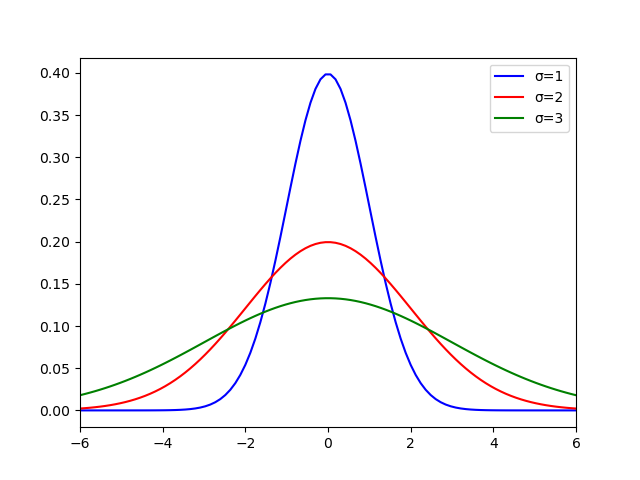
σが小さいと尖った山となり、周辺画素の影響は小さくなります。σが大きくなるにつれて、山は平坦となり、周辺画素の影響が大きくなります。ぼかしを強くしたいならσを大きくすればよいことが分かります。
画像は2次元ですので、2次元ガウス分布が必要です。2次元ガウス分布は以下式で表されます。
$$h_g(x) = \frac{1}{2\pi\sigma^2}\exp(-\frac{x^2+y^2}{2\sigma^2})$$
σ=2を代入してグラフにするとこんな感じ。
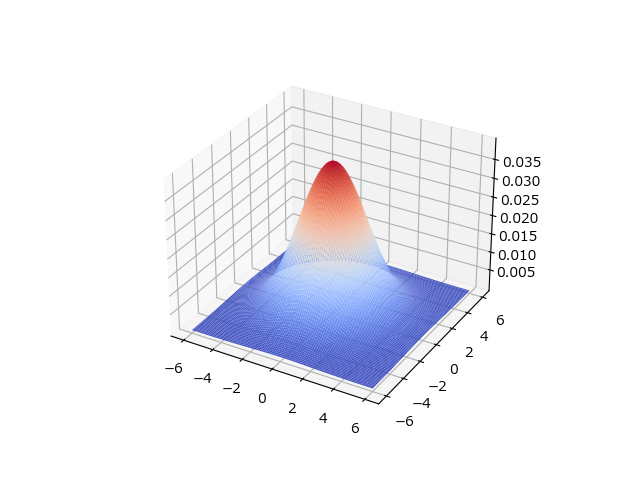
この式からNxNフィルタ係数行列を作れば、ガウシアンフィルタの出来上がりです。
OpenCVを用いたぼかし処理
PythonとOpenCVライブラリを用いれば、簡単にボックスフィルタとガウシアンフィルタで画像をぼかすことが出来ます。
ボックスフィルタのPythonプログラム
まず、ボックスフィルタのサンプルプログラムです。
import cv2 as cv
def concat_tile(im_list_2d):
return cv.vconcat([cv.hconcat(im_list_h) for im_list_h in im_list_2d])
img = cv.imread("sample.jpg") # 写真の読み込み
img = cv.resize(img, None, fx=0.5, fy=0.5) # 写真サイズを2分の1
img_blur3 = cv.blur(img, (3, 3)) # 3×3のボックスフィルタ
img_blur5 = cv.blur(img, (5, 5)) # 5×5のボックスフィルタ
img_blur7 = cv.blur(img, (7, 7)) # 7x7のボックスフィルタ
imgs = concat_tile([[img, img_blur3], [img_blur5, img_blur7]])
cv.imshow("img", imgs)
cv.imwrite("output.jpg", imgs)
if cv.waitKey(0) & 0xFF == ord('q'):
cv.destroyAllWindows()左上が元画像。右上、左下、右下がそれぞれ3×3、5×5、7×7のボックスフィルタを適用した画像です。

フィルタサイズが大きくなるほど、ぼかしが強くなっていくことが分かります。
cv.blur(img, (N, N)) # N×Nのボックスフィルタ第1引数に入力画像、第2引数にフィルタサイズを設定します。
ガウシアンフィルタのPythonプログラム
次にガウシアンフィルタのサンプルプログラムです。
import cv2 as cv
def concat_tile(im_list_2d):
return cv.vconcat([cv.hconcat(im_list_h) for im_list_h in im_list_2d])
img = cv.imread("sample.jpg") # 写真の読み込み
img = cv.resize(img, None, fx=0.5, fy=0.5) # 写真サイズを2分の1
img_gauss1 = cv.GaussianBlur(img, (0, 0), 1) # σ=1のガウシアンフィルタ
img_gauss2 = cv.GaussianBlur(img, (0, 0), 2) # σ=2のガウシアンフィルタ
img_gauss3 = cv.GaussianBlur(img, (0, 0), 3) # σ=3のガウシアンフィルタ
imgs = concat_tile([[img, img_gauss1], [img_gauss2, img_gauss3]])
cv.imshow("img", imgs)
cv.imwrite("output.jpg", imgs)
if cv.waitKey(0) & 0xFF == ord('q'):
cv.destroyAllWindows()
左上が元画像。右上、左下、右下がそれぞれσ=1、σ=2、σ=3のガウシアンフィルタを適用した画像です。
σを大きくすると、ぼかしが強くなります。
cv.GaussianBlur(img, (0, 0), N) # σ=Nのガウシアンフィルタ第1引数に入力画像、第2引数にフィルタサイズ、第3引数にσを設定します。
ここでフィルタサイズが0?と思われるでしょう。
openCVでは、フィルタサイズを0に設定するとσに応じてフィルタサイズが自動設定されます。
フィルタサイズ設定に困ったら、σだけ設定すればよいです。
ボックスフィルタとガウシアンフィルタを比べてみると、ガウシアンフィルタの方がぼかしが自然かと思われます。画像をぼかしたかったら、ガウシアンフィルタを選んでおけば間違いないです。
まとめ
本記事では、ぼかしの基本であるボックスフィルタ、ガウシアンフィルタについて解説しました。また、PythonとOpenCVで実際に写真をぼかす実践をしました。
画像をぼかしたかったら、悩まずガウシアンフィルタを選択すれば無難なことが分かりましたね。
これで、写真の主役を引き立たせるために背景をぼかしたり、プライバシー保護のため写真の顔をぼかしたりが出来ると思います。
この記事が画像処理を学ぶ皆さんのためになれば幸いです。最後まで読んで頂きありがとうございました!
独学が大変な方は、書籍やスクールを活用するのも手です。私も活用しているものを載せておきますので参考にして下さい。
 今回は、OpenCVを使って画像を平行移動・回転する方法について解説していきます。 画像の平行移動・回転は、アフィン変換という知識が必要です。 まず、アフィン変換について解説します。そして、OpenCVを使った画像処理プ […]]]>
今回は、OpenCVを使って画像を平行移動・回転する方法について解説していきます。 画像の平行移動・回転は、アフィン変換という知識が必要です。 まず、アフィン変換について解説します。そして、OpenCVを使った画像処理プ […]]]>
今回は、OpenCVを使って画像を平行移動・回転する方法について解説していきます。
画像の平行移動・回転は、アフィン変換という知識が必要です。
まず、アフィン変換について解説します。そして、OpenCVを使った画像処理プログラムを解説していきます。
アフィン変換とは
平面座標系のアフィン変換は3×3の行列を使って次式で表現できます。
$$ \left( \begin{array}{ccc} x’ \\ y’ \\ 1 \end{array} \right) = \left( \begin{array}{ccc} a & b & t_{x} \\ c & d & t_{y} \\ 0 & 0 & 1 \end{array} \right) \left( \begin{array}{ccc} x \\ y \\ 1 \end{array} \right) $$3行目って左辺が「1」、右辺も「1」でムダじゃない?
3行目は、実際の座標に加えて、仮想的な座標を付け加えています。このような座標系を同次座標系と呼びます。同次座標系による表現は、平行移動を行う上で重要となります。
平行移動
まず、アフィン変換を使って平行移動する方法を説明します。
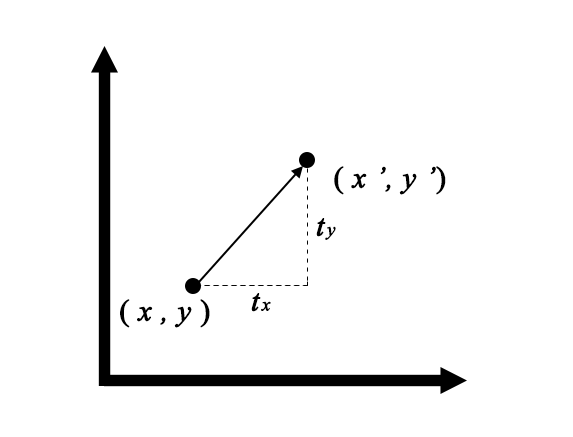
座標\((x,y)\)から\(x\)方向に\(t_{x}\)、\(y\)方向に\(t_{y}\)平行移動するとします。移動先の座標を\((x’,y’)\)としました。座標\((x’,y’)\)は、次の式で表せますね。
$$ \left( \begin{array}{ccc} x’ \\ y’ \end{array} \right) = \left( \begin{array}{ccc} x \\ y \end{array} \right) + \left( \begin{array}{ccc} t_{x} \\ t_{y} \end{array} \right) $$これを同次座標系で表現すると次の式で整理できます。
$$ \left( \begin{array}{ccc} x’ \\ y’ \\ 1 \end{array} \right) = \left( \begin{array}{ccc} 1 & 0 & t_{x} \\ 0 & 1 & t_{y} \\ 0 & 0 & 1 \end{array} \right) \left( \begin{array}{ccc} x \\ y \\ 1 \end{array} \right) $$このように平行移動は、アフィン変換の3×3行列 \(a,b,c,d\)に\(a=d=1\)、\(b=c=0\)を代入すればよいことが分かります。
回転
次にアフィン変換を使って回転する方法の説明です。
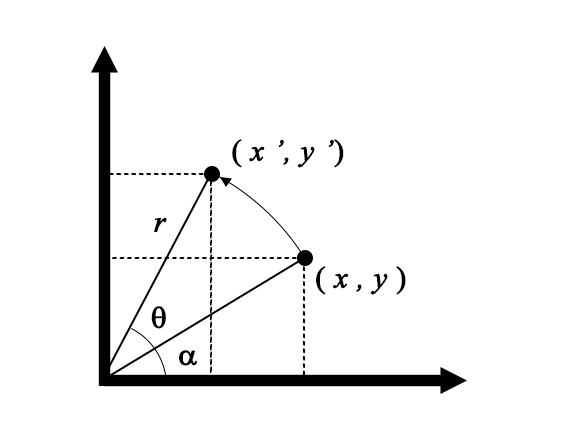
座標\((x,y)\)を原点中心に\(\theta\)角回転するとします。ここでも移動先の座標を\((x’,y’)\)としました。座標\((x’,y’)\)は次の式で表すことが出来ます。
$$ \left( \begin{array}{ccc} x’ \\ y’ \end{array} \right) = \left( \begin{array}{ccc} r \cos (\theta + \alpha) \\ r \sin (\theta + \alpha) \end{array} \right) $$ここで三角関数の加法定理を使うと
$$ \left( \begin{array}{ccc} x’ \\ y’ \end{array} \right) = \left( \begin{array}{ccc} r \cos \theta \cos \alpha – r \sin \theta \sin \alpha \\ r \sin \theta \sin \alpha + r \cos \theta \cos \alpha \end{array} \right) $$座標\((x,y)\)は
$$ \left( \begin{array}{ccc} x \\ y \end{array} \right) = \left( \begin{array}{ccc} r \cos \alpha \\ r \sin \alpha \end{array} \right) $$ですので、座標\((x’,y’)\)は次式となります。
$$ \left( \begin{array}{ccc} x’ \\ y’ \end{array} \right) = \left( \begin{array}{ccc} x \cos \theta – y \sin \theta \\ x \sin \theta + y \cos \theta \end{array} \right) $$式を整理すると
$$ \left( \begin{array}{ccc} x’ \\ y’ \end{array} \right) = \left( \begin{array}{ccc} \cos \theta & – \sin \theta \\ \sin \theta & \cos \theta \end{array} \right) \left( \begin{array}{ccc} x \\ y \end{array} \right) $$最後に、同次座標系で表現すると次式になります。
$$ \left( \begin{array}{ccc} x’ \\ y’ \\ 1 \end{array} \right) = \left( \begin{array}{ccc} \cos \theta & -\sin \theta & 0 \\ \sin \theta & \cos \theta & 0 \\ 0 & 0 & 1 \end{array} \right) \left( \begin{array}{ccc} x \\ y \\ 1 \end{array} \right) $$回転は、アフィン変換の3×3行列\(a,b,c,d\)に\(a=\cos\theta\)、\(b=-\sin\theta\)、\(c=\sin\theta\)、\(d=\cos\theta\)、\(t_{x}=0\)、\(t_{y}=0\)を代入すればよいことが分かります。
このように平行移動、回転はアフィン変換で実現できます。
OpenCVで画像の平行移動・回転
アフィン変換について理解できたと思いますので、本題のOpenCVで画像を平行移動・回転していきましょう!
今回は▼の画像を平行移動・回転します。画像は何でもよいですよ。

平行移動のプログラム
画像を平行移動するサンプルプログラムです。
import cv2 as cv
import numpy as np
#画像データの読み込み
img = cv.imread("sample.jpg")
height, width = img.shape[:2]
tx, ty = 100, 100
#アフィン変換: 平行移動
mv_mat = np.float32([[1, 0, tx],[0, 1, ty]])
afin_img = cv.warpAffine(img, mv_mat, (width, height))
cv.imshow("img", afin_img)
if cv.waitKey(0) & 0xFF == ord('q'):
cv.destroyAllWindows()水平方向に100、垂直方向に100移動させるため、\(t_{x}=100\)、\(t_{y}=100\)としました。アフィン変換の3×3行列 「mv_mat」を作成します。OpenCVでは、画像をアフィン変換するためのwarpAffine関数が用意されていますので、第1引数に移動対象の画像、第2引数にアフィン変換の行列、第3引数に出力画像サイズを指定しましょう。
出力結果が▼となります。

回転のプログラム
画像を回転するサンプルプログラムです。
import cv2 as cv
import numpy as np
#画像データの読み込み
img = cv.imread("sample.jpg")
height, width = img.shape[:2]
#アフィン変換: 回転
rot_mat = cv.getRotationMatrix2D((width/2, height/2), 45, 1)
afin_img = cv.warpAffine(img, rot_mat, (width, height))
cv.imshow("img", afin_img)
if cv.waitKey(0) & 0xFF == ord('q'):
cv.destroyAllWindows()前章で解説した回転のアフィン変換は、原点を中心に行われます。任意の点を中心に回転したい場合は、平行移動→回転→平行移動を繰り返す必要があります。OpenCVは、この処理を一括で行ってくれる関数があります。それがgetRotationMatrix2D関数です。第1引数に回転中心の座標、第2引数に角度、第3引数に拡大率を指定します。getRotationMatrix2D関数を実行するとアフィン変換の行列が戻り値として返ってきます。
出力結果が▼となります。

画像の中央点を中心に画像が回転されました。
まとめ
今回は、OpenCVを使って画像を平行移動・回転する方法について解説しました。
- 画像を平行移動・回転するためのアフィン変換について解説
- OpenCVで画像を平行移動・回転するプログラムを解説
画像処理ソフトがどうやって画像を平行移動・回転しているか理解出来たのではないかと思います。
今回の記事が皆さんのPython学習に役立つなら幸いです。
Python独学が大変な方は、書籍やスクールを活用するのも手です。

 今回はmatplotlibを使ってヒストグラムを描画する方法について解説します。 ヒストグラムの描画方法 デフォルト描画方法 ヒストグラムはpyplotモジュールのhist関数を用いることで描くことが出来ます。 キーワー […]]]>
今回はmatplotlibを使ってヒストグラムを描画する方法について解説します。 ヒストグラムの描画方法 デフォルト描画方法 ヒストグラムはpyplotモジュールのhist関数を用いることで描くことが出来ます。 キーワー […]]]>
今回はmatplotlibを使ってヒストグラムを描画する方法について解説します。
ヒストグラムの描画方法
デフォルト描画方法
ヒストグラムはpyplotモジュールのhist関数を用いることで描くことが出来ます。
import numpy as np
import matplotlib.pyplot as plt
x = np.random.normal(50, 10, 1000)
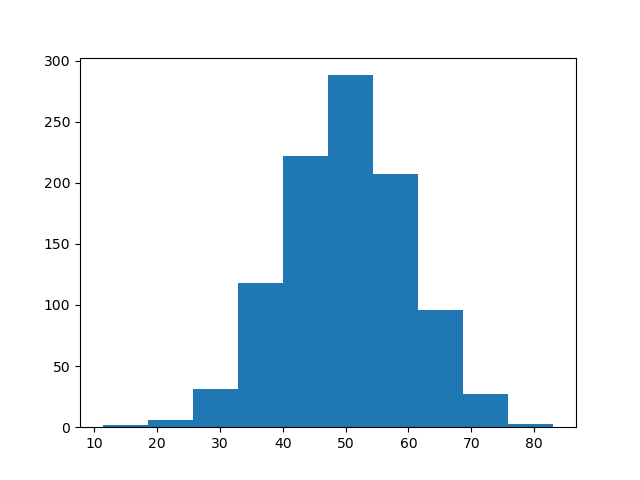
plt.hist(x)
plt.show()キーワード引数を指定しない場合は、階級数は10となります。
階級数の設定方法
階級数を設定するには、「bins」に「階級数」を渡します。
plt.hist(x, bins=20)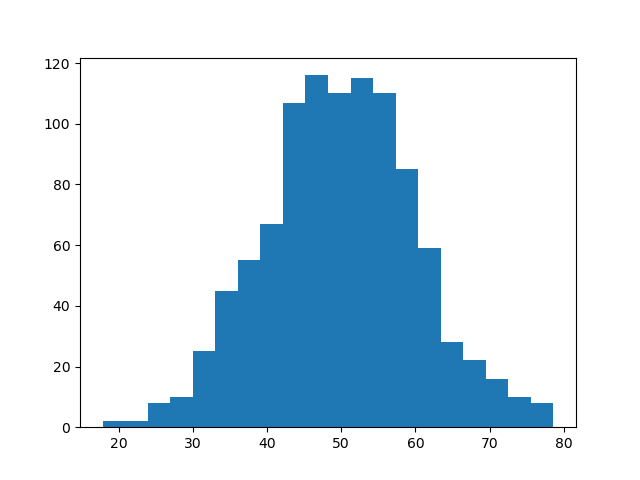
階級範囲の設定方法
階級範囲を設定するには、「range」に「(最小値, 最大値)」を渡します。
plt.hist(x, range=(40,80))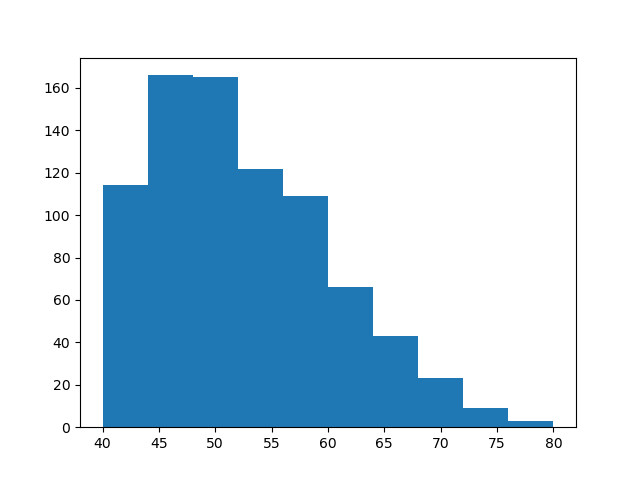
正規化方法
正規化するには、「density」に「True」を渡します。
plt.hist(x, density=True)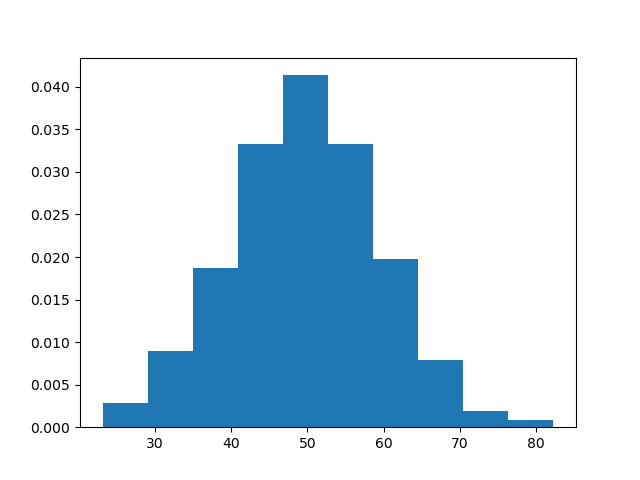
グラフ色の設定方法
グラフ色を設定するには、「color」に「色値」を渡します。
plt.hist(x, color='r')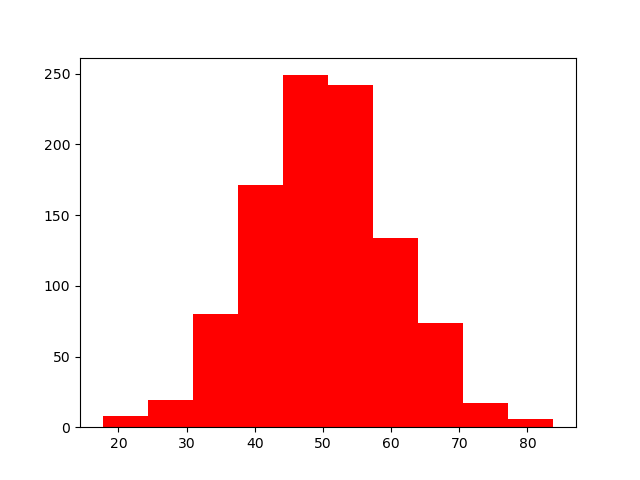
まとめ
matplotlibを使ってヒストグラムを描画する方法について解説しました。
今回の記事が皆さんのPython学習に役立つなら幸いです。
Python独学が大変な方は、書籍やスクールを活用するのも手です。
最後までお読み頂きありがとうございました。
]]> M5StickCで計測した加速度データをUSBを経由してPCでロギングする実験をしたので記事にしてみました。 PCロギングは、3種類の方法を紹介します。 1つ目はターミナルソフト TeraTermを使ったロギング。2つ目 […]]]>
M5StickCで計測した加速度データをUSBを経由してPCでロギングする実験をしたので記事にしてみました。 PCロギングは、3種類の方法を紹介します。 1つ目はターミナルソフト TeraTermを使ったロギング。2つ目 […]]]>
M5StickCで計測した加速度データをUSBを経由してPCでロギングする実験をしたので記事にしてみました。
PCロギングは、3種類の方法を紹介します。
1つ目はターミナルソフト TeraTermを使ったロギング。2つ目はArduino IDEのシリアルモニタ、シリアルプロッタを使ったロギング。3つ目はPythonでのロギングです。
この記事はこんな人におすすめ!
- M5Stack/M5Stickのシリアル通信方法を学びたい人
- M5Stack/M5StickCとPC間をUSB経由でデータ通信したい人
- M5Stack/M5StickCが取得したデータをPCでロギングする方法を学びたい人
この記事のゴールはこちら▼
それでは始めていきましょう!
準備するもの
- M5Stack or M5StickC (今回はM5StickC Plusを使用しています)
- USBケーブル
- PC
- Tera Term
- Arduino IDE
- Python開発環境
通信方法
M5StickC側からデータ送信する方法
加速度データを送信するM5StickC側のサンプルプログラムを以下に示します。
#include <M5StickCPlus.h>
float x, y, z; // 加速度データを格納
bool isSend = false; // データ送信フラグ
void setup() {
M5.begin();
M5.IMU.Init();
Serial.begin(57600);
M5.Lcd.setRotation(3);
M5.Lcd.setCursor(0,0,4);
M5.Lcd.println("Not Send");
}
void loop() {
M5.update();
if(M5.BtnA.wasPressed()){
isSend = !isSend;
if(isSend){
M5.Lcd.fillScreen(BLACK);
M5.Lcd.setCursor(0,0,4);
M5.Lcd.println("Send");
}
else{
M5.Lcd.fillScreen(BLACK);
M5.Lcd.setCursor(0,0,4);
M5.Lcd.println("Not Send");
}
}
if(isSend){
// 加速度データ取得
M5.IMU.getAccelData(&x, &y, &z);
// 加速度データを送信
Serial.printf("%5.3f,%5.3f,%5.3f\n", x, y, z);
}
delay(200);
}シリアル通信によるデータ送信方法はとても簡単です。
まず、Serial.begin()関数を呼び出し、シリアル通信のデータ転送速度を設定します。単位は「bps(ビット/秒)」です。
データを送信するには、Serial.printf()の引数に送信したいデータを指定するだけです。
PC側でデータを受信する方法
Tera Termを使ったデータ受信
ターミナルソフト「Tera Term」でデータ受信する方法について解説します。
Tera Termを起動したらTCP/IP、シリアルが選択できますので、シリアルを選択しましょう。
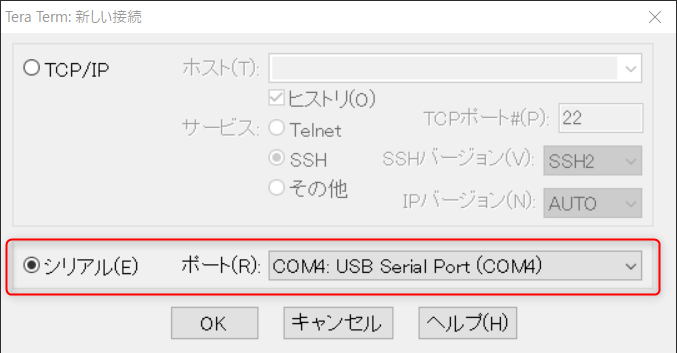
次に「設定」から「シリアルポート」を選択し、スピードをM5StickCで設定した値にします。今回のサンプルプログラムでは、57600[bps」です。
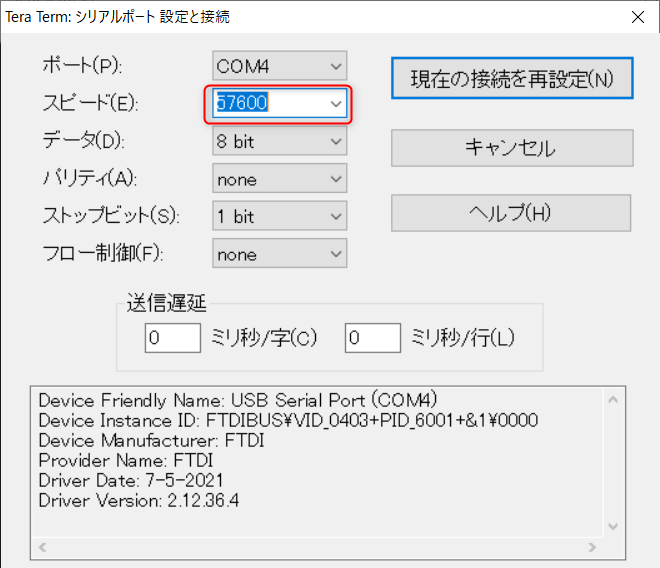
続いて改行コードの設定です。M5StickCは、改行を「\n」で指定しています。そのため、「設定」から「端末」を選択し、改行コードを「LF」に変更します。
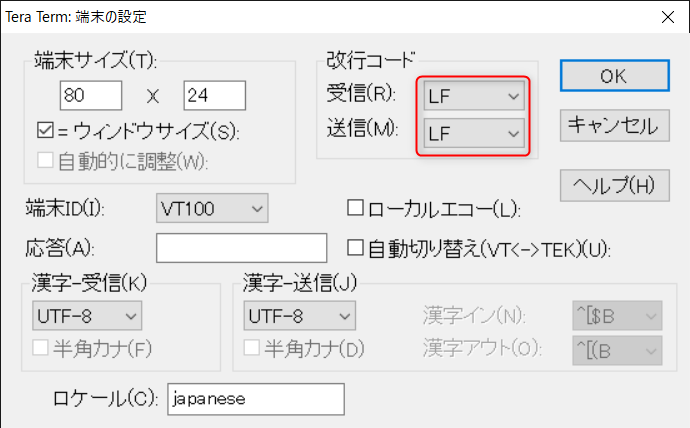
これでTera Termの設定は完了です。M5StickのAボタン(M5と彫られたボタン)を押しましょう。
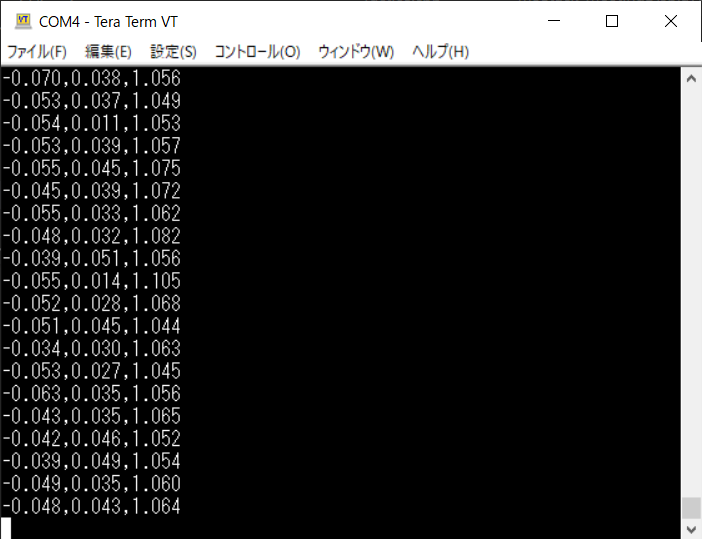
0.2秒ごとに加速度センサのデータを受信することが出来ます。
Arduino IDEのシリアルモニタ、シリアルプロッタを使ったデータ受信
Arduino IDEにもシリアル通信する機能があります。シリアルモニタとシリアルプロッタです。
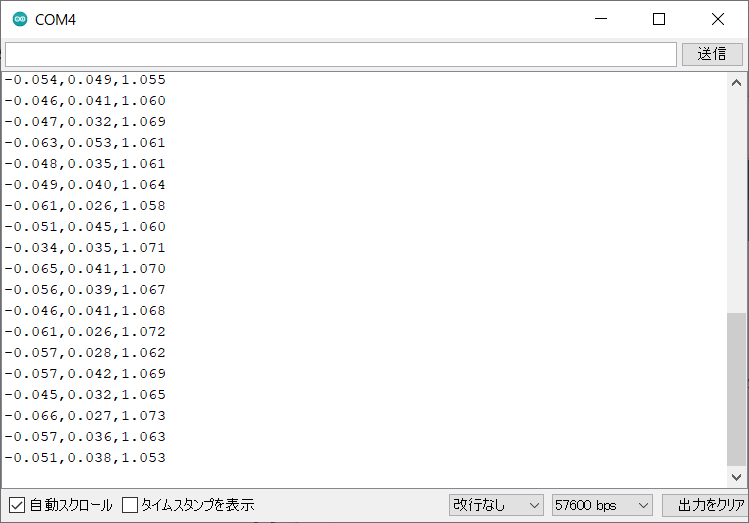
まずシリアルモニタについての解説です。
Arduino IDEを起動し、「ツール」から「シリアルモニタ」を選択して下さい。
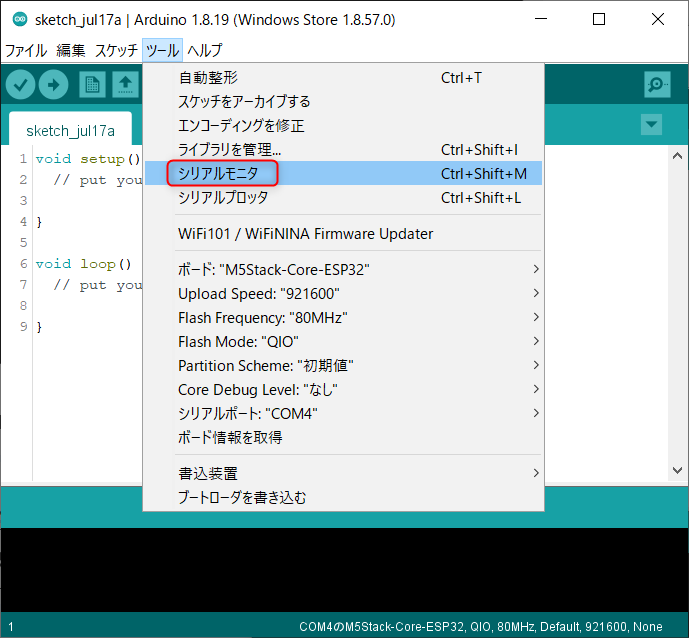
M5StickCのAボタンを押すと、Tera Termのときと同様に加速度センサのデータを受信することが出来ます。
次にシリアルプロッタです。シリアルプロッタは受信したデータを時系列で表示することが出来ます。
「ツール」から「シリアルプロッタ」を選択して下さい。
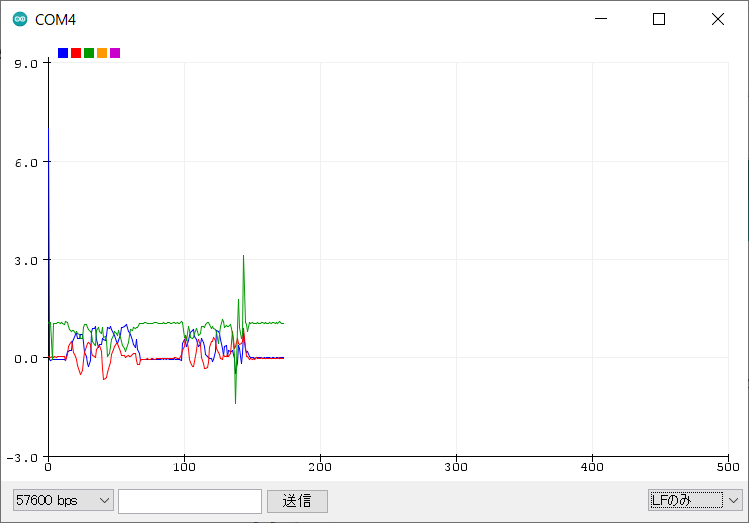
M5StickCのAボタンを押すと、受信したデータが時系列で表示されていきます。
簡易的な機能なので、縦軸などの変更は出来ないようです。
Pythonを使ったデータ受信
Pythonを使ったデータ受信は、プログラムを書く必要がありますが、プログラム次第でどんな表示も出来ます。今回は、TeraTerm、Arduino IDEのシリアルモニタと同様、受信データを順に表示するようにしました。
Pythonには、シリアル通信を簡単に実装することが出来る「pySerial」モジュールがありますので、これを使いました。
import serial
import time
ser = serial.Serial("COM4", 57600, timeout=0.1)
time.sleep(2)
try:
while True:
if ser.in_waiting > 0: # シリアル通信 受信待ち
bytes = ser.readline()
result, buf = bytes.decode('utf-8').split('\n')
data = list(map(float, result.split(',')))
print("AccX: {0}, AccY: {1}, AccZ: {2}".format(data[0], data[1], data[2]))
time.sleep(0.2)
except KeyboardInterrupt:
pass
print('program end')
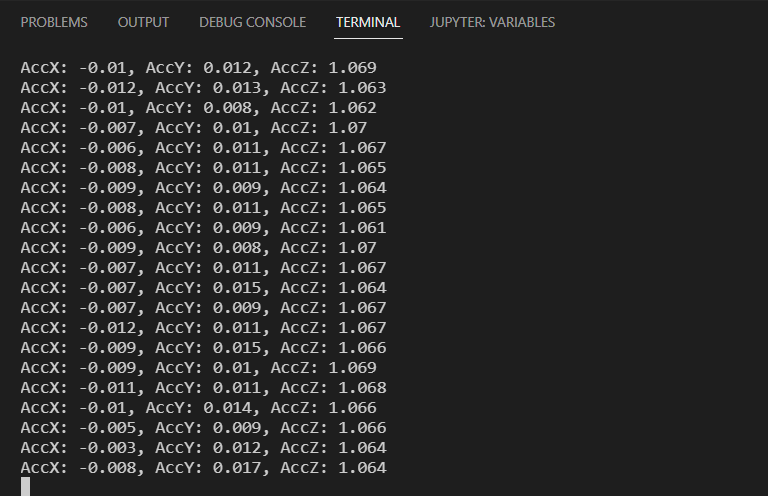
ser.close()まず、serial.Serialクラスを呼び出します。第1引数にはCOMポート番号、第2引数にはデータ転送速度を設定します。
データを受信したときのみターミナル表示にしたかったので、if文の条件としてser.in_waitingが0より大きいときにしました。ser.in_waitingは受信データのバイト数を戻り値として返します。
無限ループを避けるため、「ctrl + c」でプログラムを終了するようにしました。
M5StickCのAボタンを押すと、ターミナル上に加速度データが表示されていきます。
まとめ
M5StickCで計測した加速度データをUSBを経由してPCでロギングする方法について、TeraTermを使ったロギング、Arduino IDEのシリアルモニタ、シリアルプロッタを使ったロギング、Pythonでのロギングを例に挙げて解説しました。
TeraTerm、Arduino IDEはプログラムを書く必要が無く、手軽にデータロギングすることが出来ます。
一方、Pythonは自分でプログラムを書く必要がありますが、matplotlibなどのグラフ描画ライブラリを使ってグラフ化したり、csvにデータを書き出すなど応用が効くと思います。
以上、今回の記事が皆さんの参考になりましたら幸いです。
]]> Pythonで2次元リストを作成する場合、多重ループを使うので、どうしてもプログラム行数が増えてしまいますよね。 Pythonには内包(ないほう)表記という記述方法があって、これを使えば1行で2次元リストを作成出来ます。 […]]]>
Pythonで2次元リストを作成する場合、多重ループを使うので、どうしてもプログラム行数が増えてしまいますよね。 Pythonには内包(ないほう)表記という記述方法があって、これを使えば1行で2次元リストを作成出来ます。 […]]]>
Pythonで2次元リストを作成する場合、多重ループを使うので、どうしてもプログラム行数が増えてしまいますよね。
Pythonには内包(ないほう)表記という記述方法があって、これを使えば1行で2次元リストを作成出来ます。
こんな便利な方法はしっかりと覚えておくべきです。
今回は内包表記について解説します。
この記事はこんな人におすすめ!
- Pythonを勉強し始めた初心者
- プログラムを簡潔に書きたい人
- 2次元リストの作成方法が分からない人
それでは始めましょう!
内包表記を使った2次元リスト作成サンプル
内包表記を使っった2次元リストの作成例として、行番号と列番号が同じ場合は「1」、異なる場合は「0」の4行3列の2次元リスト作成を挙げます。
outList = [[1 if i==j else 0 for j in range(1,4)] for i in range(1,5)]
print(outList)[実行結果]
[[1, 0, 0], [0, 1, 0], [0, 0, 1], [0, 0, 0]]内包表記を使えば2次元リスト作成が1行で済みます。
それに対して内包表記を使わない場合の記述は以下となります。
outList = []
for i in range(1,5):
buff = []
for j in range(1,4):
if i==j:
buff += [1]
else:
buff += [0]
outList += [buff]
print(outList)内包表記を使わない場合は9行も記述が必要です。
このように内包表記を使えばプログラムが非常に簡潔になるので、内包表記を覚えておくメリットは大きいと思います。
内包表記による2次元リスト作成は一見難しそうに見えますが、1つ1つ分解していけば直ぐ理解出来るでしょう。
for文、if文それぞれの簡単な例で解説していきます。
for文の内包表記
for文の内包表記を解説するため、0から4までのリスト作成例を挙げます。内包表記を使った記述は以下となります。
outList = [i for i in range(5)][実行結果]
[0, 1, 2, 3, 4]これを内包表記を使わない記述にすると以下になります。
outList = []
for i in range(5):
outList += [i]
print(outList)両者を比較すると、内包表記を使った記述はfor文の処理を「for」の手前に持ってきた形になっていますね。
for文の内包表記は、処理を「for」の手前に持ってくると覚えましょう。
if文の内包表記
次にif文の内包表記を解説するため、リスト順が3番目までは「0」、4番目以降は「1」を代入するリスト作成例を挙げます。内包表記を使った記述は以下となります。
outList = [1 if i>2 else 0 for i in range(5)][実行結果]
[0, 0, 0, 1, 1]内包表記を使わない記述は
outList = []
for i in range(5):
if i>2:
outList += [1]
else:
outList += [0]
print(outList)両者を比較すると、内包表記を使った記述はif文の処理を「if」の手前に持ってきて、else文の処理を「else」の後ろに持ってきた形になっています。
if文の内包表記は、ifの処理を「if」の手前に、elseの処理を「else」の後ろに持ってくると覚えましょう。
内包表記を使った2次元リスト作成の解説
for文、if文の内包表記が理解出来たと思いますので、2次元リスト作成の例を解説しましょう。
内包表記を使用しない例は以下でしたね。
outList = []
for i in range(1,5):
buff = []
for j in range(1,4):
if i==j:
buff += [1]
else:
buff += [0]
outList += [buff]
print(outList)多重ループがある複雑な表記でも、行のfor文、列のfor文、if文に分解し、1つずつ内包表記に変更していけばよいです。まずif文です。
outList = []
for i in range(1,5):
buff = []
for j in range(1,4):
buff += [1 if i==j else 0]
outList += [buff]
print(outList)次に列のfor文を内包表記に変更してみます。
outList = []
for i in range(1,5):
outList += [[1 if i==j else 0 for j in range(1,4)]]
print(outList)最後に行のfor文を内包表記に変更すると
outList = [[1 if i==j else 0 for j in range(1,4)] for i in range(1,5)]
print(outList)このように多重ループも1つずつ分解して考えれば、内包表記にすることが出来ます。
まとめ
以上、2次元リストの作成を内包表記で簡潔に書く方法の解説でした。
内包表記を覚えておけば、多重ループがあり長くなりがちな2次元リスト作成も簡潔に記述することが出来ます。
こんな便利な方法はしっかりと覚えておきましょう!
今回の記事が皆さんのPython学習に役立つなら幸いです。
独りでPython学習するのは大変だなと思う方は、書籍やスクールを活用するのも手です。
最後までお読み頂きありがとうございました。
]]>